



Mawiają, żeby kuć żelazo póki gorące. A jak tak, to skoro kilka dni temu Grzegorz Zembrowski na łamach podcastu Cyber, Cyber… dzielił się wiedzą, dotyczącą walki z phishingiem, warto przeczytać, co o tym napisał na łamach Raportu CERT Orange Polska 2021 o roli sztucznej inteligencji i uczenia maszynowego. Wszystkie edycje Raportu znajdziecie tutaj.
Rozpoznawanie domen przy pomocy metod Machine Learning nie jest zadaniem prostym. Przegląd literatury zwykle kończy się na stwierdzeniu, że dany sposób jest albo technicznie niemal niewykonalny (fizyczne pobranie milionów stron dziennie oraz analiza ich zawartości – możliwe dla ruchu przychodzącego do firmy, nie na poziomie krajowych serwerów DNS), lub jest to czysto akademickie podejście na zbalansowanym, oznaczonym i skończonym zbiorze danych. Tymczasem rzeczywistość jest dużo bardziej skomplikowana.
Naszym przeciwnikiem są ludzie bardzo zdeterminowani w kierunku osiągnięcia celów, o nieograniczonej inwencji. Każda nowa domena phishingowa różni się mniej lub bardziej od poprzedniej znanej, do tego zbiór uczący nigdy nie jest w 100% prawidłowo oznaczony i nieustannie się zmienia. Poniżej przykład podejścia, stosowanego w przypadku CyberTarczy, które sprawdza się znakomicie. Kiedy piszę ten artykuł, liczba zablokowanych domen zbliża się do poziomu 150 tysięcy rocznie.
Skala
Liczba domen do przetworzenia jest… duża. Spójrzmy na dane z przykładowych 7 dni i unikalne domeny z dwóch największych źródeł:
- stream certyfikatów – 40 mln
- serwery DNS – 20 mln (próbka)
- zweryfikowane i zablokowane domeny z tego samego okresu: 3500-4500
Szansa na znalezienie domeny phishingowej wynosi zatem około 1:15000. To dużo, jeśli to my mamy ją znaleźć, jednak mało, jeśli miałby na nią trafić internauta. Podejście regexpowe sprawdzi się tylko w bardzo ograniczonym zakresie. Dążymy do pełnej automatyki procesu, nie chcemy brać pod uwagę ręcznej edycji słów kluczowych w przyszłości.
Przykład
Obejrzyjmy to co dotychczas udało się złowić. Skupimy się na danych z jednego miesiąca 2021 roku – września, w którym zbiór był najbogatszy.
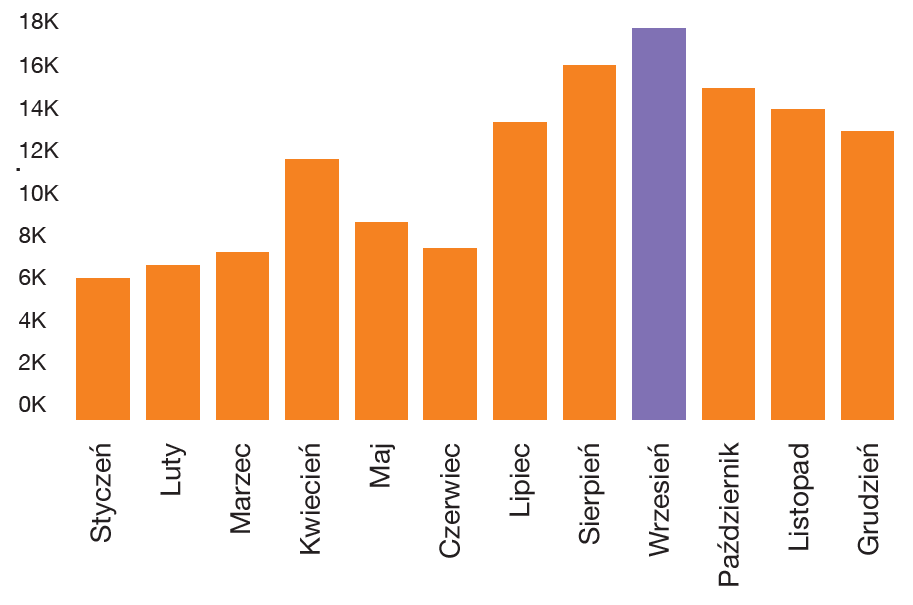
Mamy do analizy ponad 17 tys. domen. Spróbujmy je automatycznie podzielić na klastry o podobnych cechach, najlepiej na podstawie łatwo dostępnych cech. Jeżeli klastrowanie się powiedzie możemy zakładać, że klasyfikacja phishing/not phishing na podstawie podobnych cech również powinna się udać. Dla uproszczenia odetnijmy jeszcze prefix ‘www’. Zostanie około 9300 domen.
Cechy
Popatrzmy na najłatwiej dostępne informacje infrastrukturalne. W przypadku serwera DNS będzie to adres IP, na który domena się rozwiązywała. Poniżej najpopularniejsze IP:
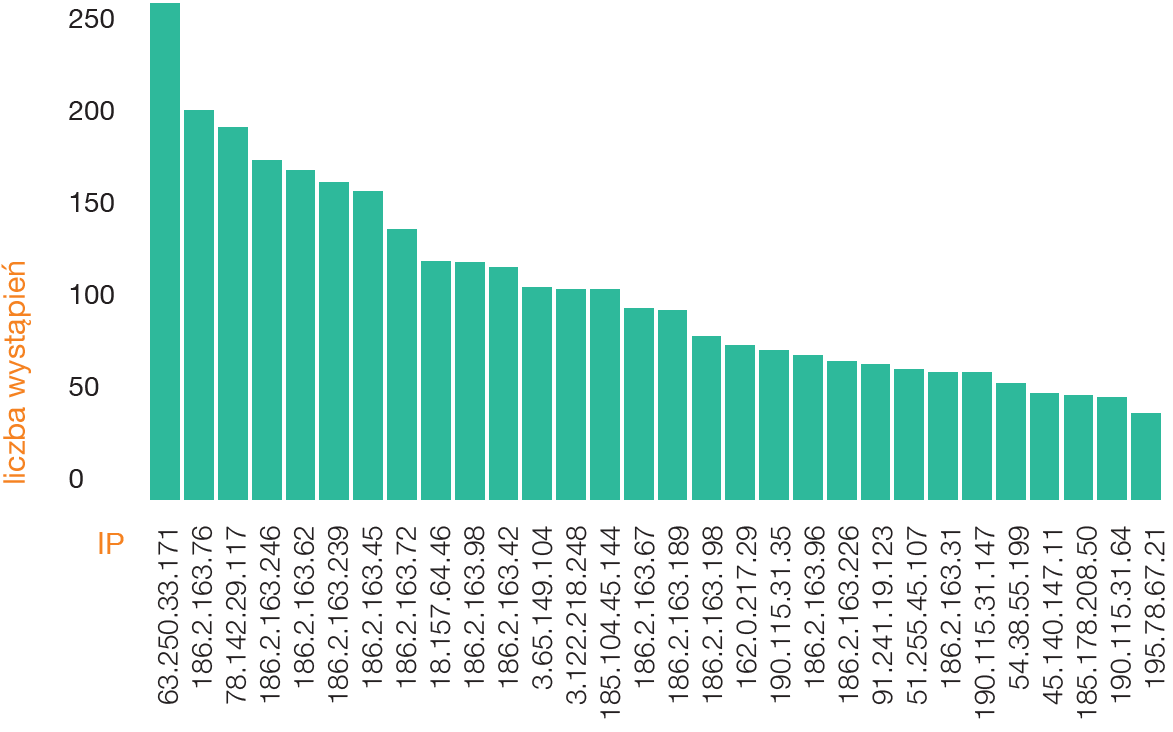
Jak widać istnieją adresy IP, które są szczególnie oblegane. Jednak wcale nie jest regułą to, że jeśli na danym IP był phishing, pojawi się tam kolejna domena phishingowa. Równie dobrze może być tam tysiąc legalnych stron. Warto dodać, że liczba unikalnych IPv4 w analizowany zbiorze to aż 1689.
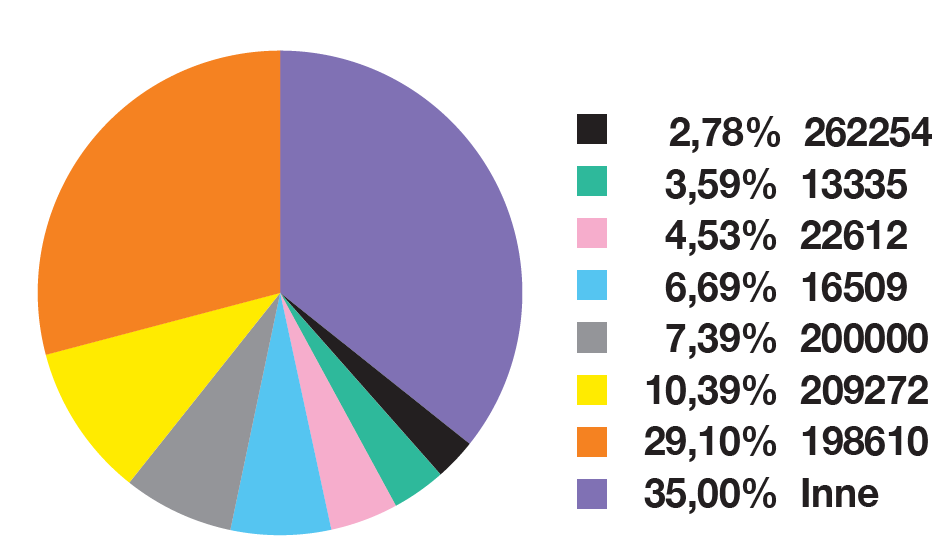
Cechą pochodną adresu IP, dostępną niewielkim kosztem jest ASN. Rozkład pośród domen phishnigowych w badanym okresie wyglądał tak:
Gdy przyjrzyjmy się subdomenom stron, które rozwiązują się na IP z popularniejszego AS-a, wyłania się dosyć oczywisty obraz:
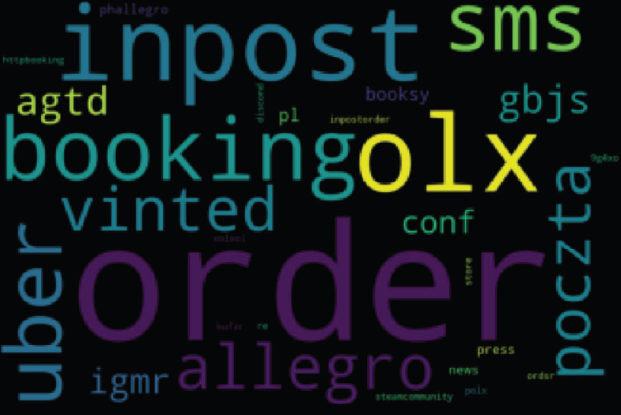
W wielu przypadkach nie da się jednak nawet zrobić chmury słów bez dodatkowej obróbki, bowiem słowa zwyczajnie się nie powtarzają. Domeny, które rozwiązywały się na adresy IP z dwóch przykładowych AS-ów:
| 42745 | 398101 |
| nngoo.xyz wgoo.xyz rgoo.xyz ccgoo.xyz nnngo.xyz ooogo.xyz togoo.xyz poogo.xyz goosoo.in | miklesratoni.online antonprestol.online nikrastere.online lopesrodero.online diklesropty.online dokolertkola.online dedertes.online deukraber.online dokortes.online |
Jeśli spojrzymy na częściowe dane z Whois:
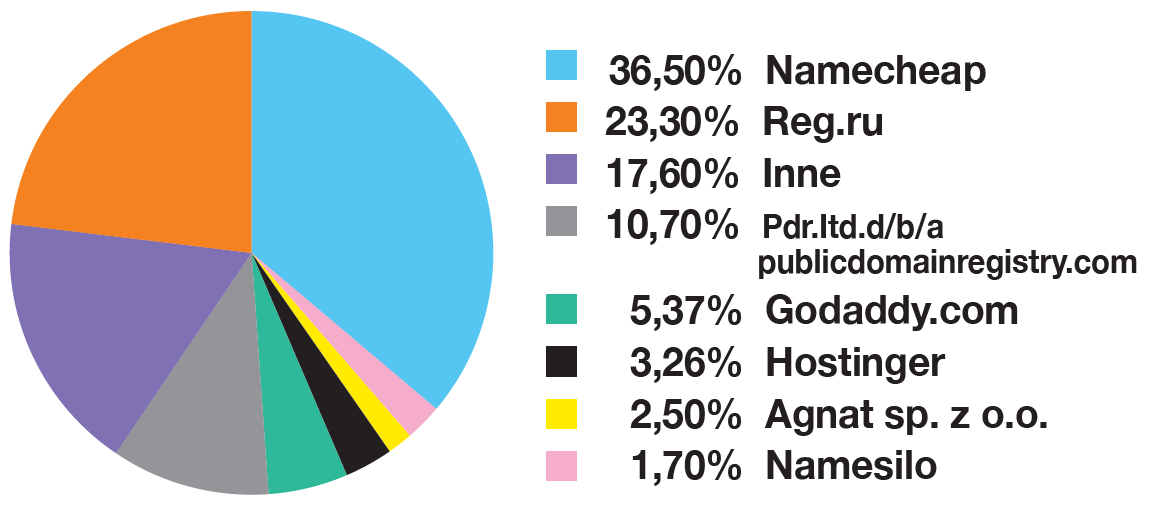
Tu owszem, mamy liderów, jednak w czołówce znajduje się jeszcze paru pretendentów, sama lista też stosunkowo krótka (ok. 100 unikalnych wartości). Problemem tej zmiennej jest jej ograniczona dostępność w masowych zastosowaniach. Doskonały przykład ograniczenia z jakimi trzeba się mierzyć.
Trochę inaczej sprawa ma się w przypadku wystawcy certyfikatów, przewaga jednego z nich jest bezdyskusyjna, a dane na ten temat mogą być łatwo dostępne:
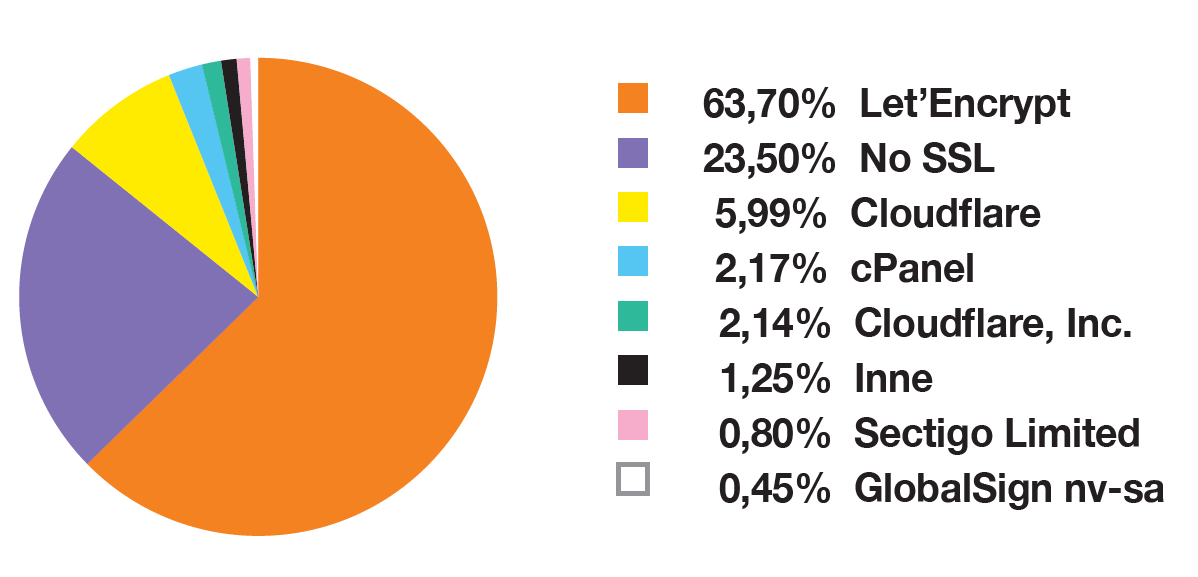
Warto zaznaczyć, że prawie 80% blokowanych domen posiada certyfikat SSL.
Kolejną cechą, którą możemy brać pod uwagę jest czas, przez jaki dana domena jest odwiedzana przez ofiary. Takie dane widzimy na serwerach DNS. Na osi x przybliżony czas, w minutach, efektywnego użycia domeny w ataku (między pierwszym i ostatnim odbiciem). Na osi y – skumulowany procent domen.
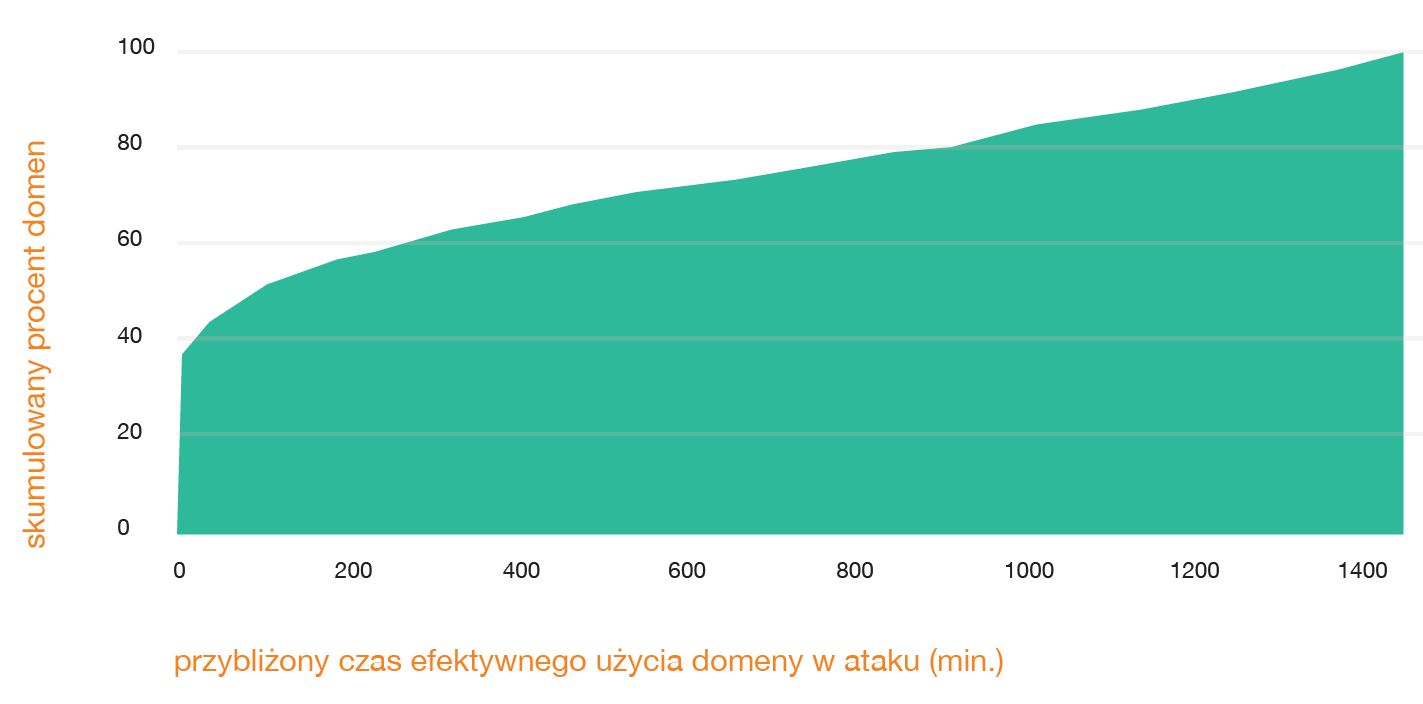
40% domen kończy swoją aktywność w ciągu kilku minut od wizyty pierwszej ofiary! Dlatego tak ważny jest czas szybkiej reakcji na pojawiającą się domenę. Oznacza to, że blokada domeny na podstawie zgłoszenia osoby poszkodowanej jest w blisko połowie przypadków już zbyt późna/niepotrzebna. Z drugiej strony, tak krótki czas aktywności jest niejako wymuszony naszym działaniem! Gdybyśmy zrezygnowali nawet z takiej spóźnionej blokady, czas aktywności domen wzrósłby w sposób naturalny. To przykład cechy, której praktycznie nie używamy, bo przecież najlepiej zablokować domenę zanim pojawi się pierwsza ofiara.
Pośród cech, którymi możemy się posługiwać, jedna wydaje się najważniejsza: adres strony. Jednak tu przestają działać typowe podejścia Natural Language Processing. Nie wykonamy lematyzacji (sprowadzania słowa do formy podstawowej) na domenie „ooogo.xyz”, a odległość Levenshteina (liczba kroków potrzebnych do zamiany jednego słowa w drugie) zda się na nic przy parze: „eiiegrolokalnie.xyz” i „lokaineallegro.xyz”.
Poniżej przykład automatycznego podziału na klastry tylko na podstawie tekstu (Dla zainteresowanych i bez wchodzenia w szczegóły: wykres TF-IDF+PCA, kolory TF-IDF+KMeans):
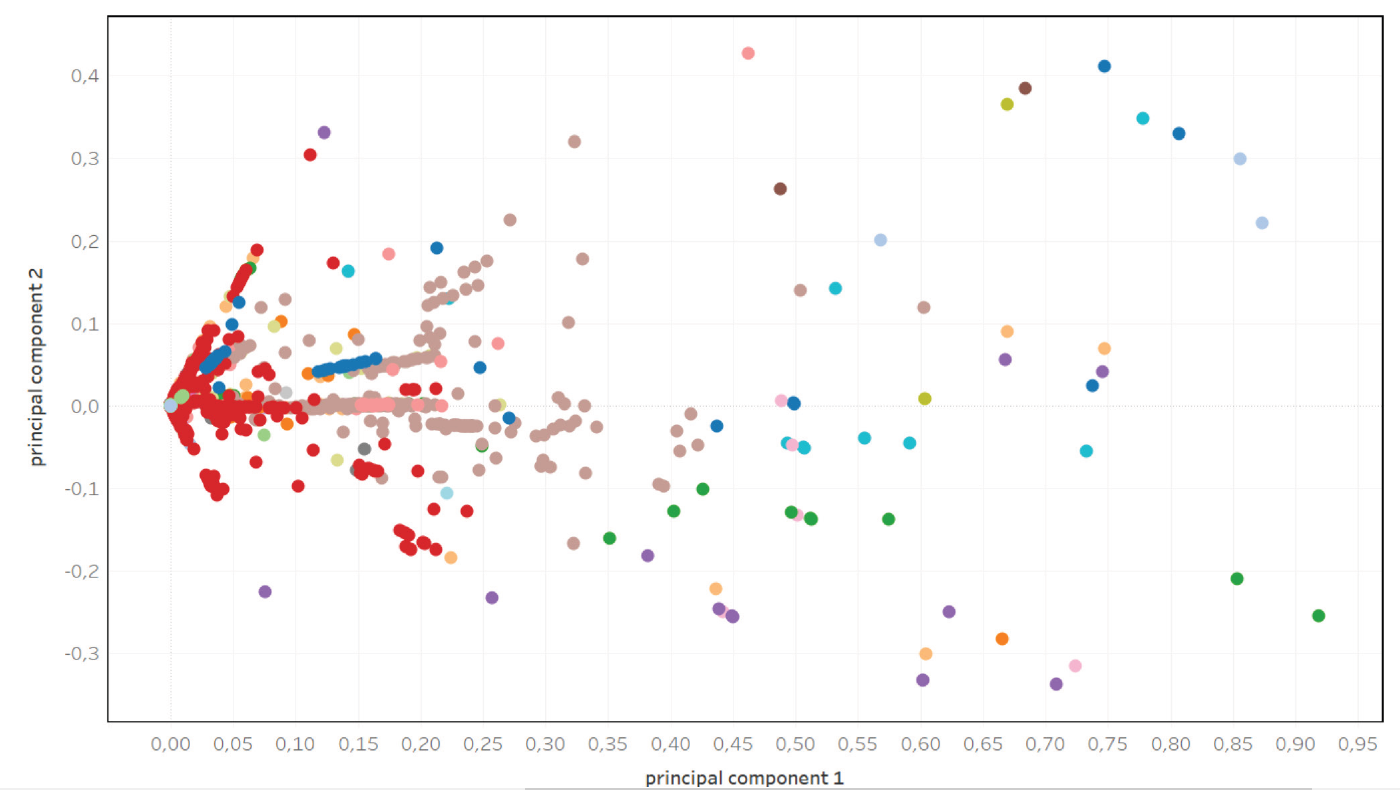
Czy coś wynika z powyższego wykresu? Niespecjalnie. Mamy jakieś klastry (ten sam kolor) jednak ich pozycja jest rozstrzelona i trudno o znalezienie jakiejś reguły. Podobnie sytuacja wygląda na wykresie t-SNE:
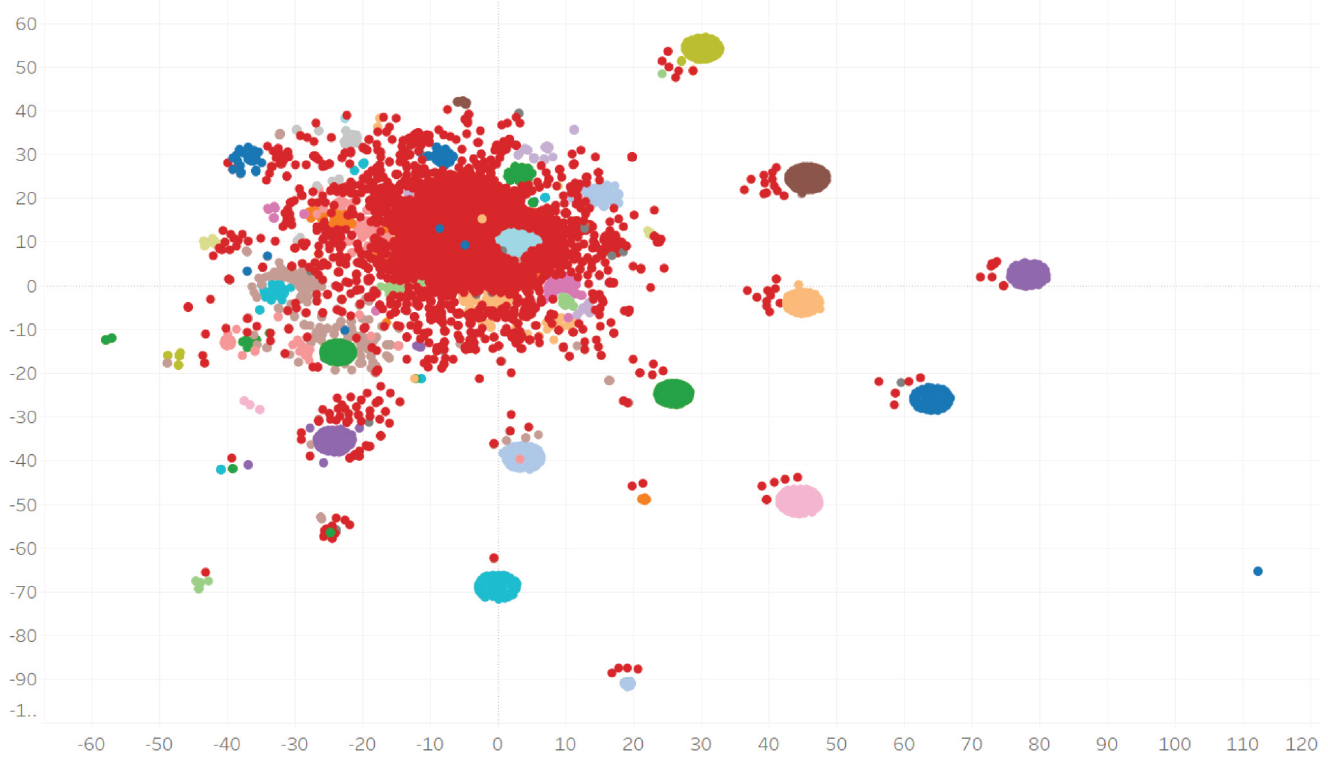
Tu pojawiają się pewne prawidłowości, choć nie brak też błędów. Zbliżenie grupy w pobliżu przecięcia współrzędnych x=40 i y=-50:
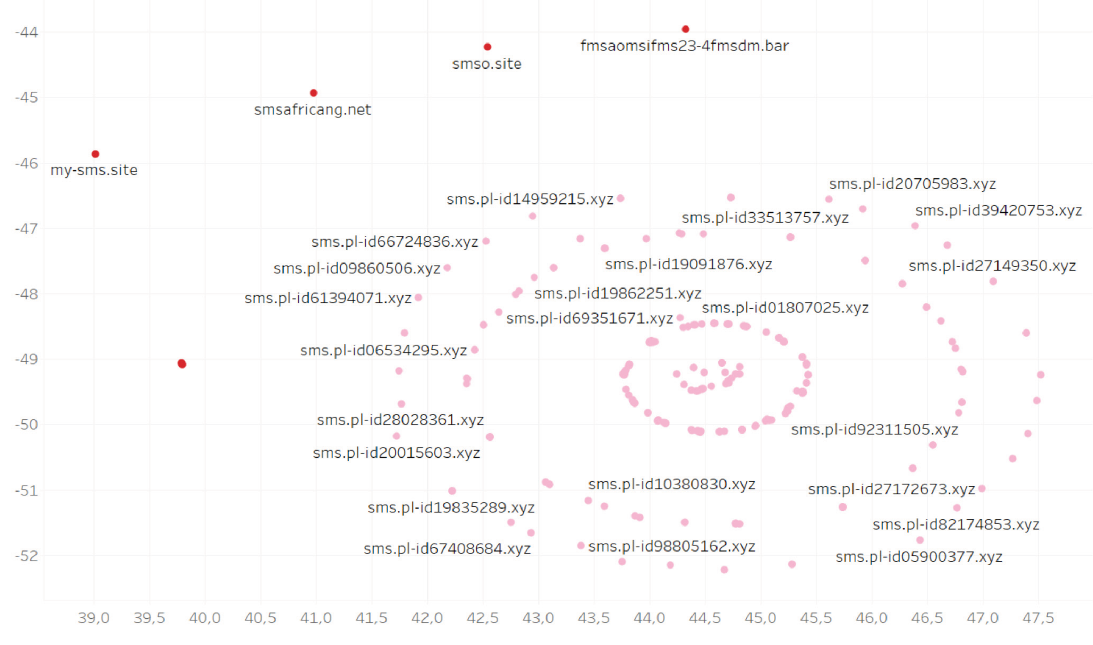
Obok domen sms.pl-id… widzimy też my-sms…smsafricang. Algorytm uznał, że fraza „sms” jest tu najważniejsza, a przecież ciąg znaków „sms” w nazwie domeny to nic złego. Innymi słowy, tekst – owszem – ma znaczenie, jednak to nie wszystko.
Sprawdźmy zatem jak podobna operacja powiedzie nam się na wspomnianych wcześniej cechach takich jak IP, ASN, registrar, itd. t-SNE dla tych cech wygląda już dużo lepiej:
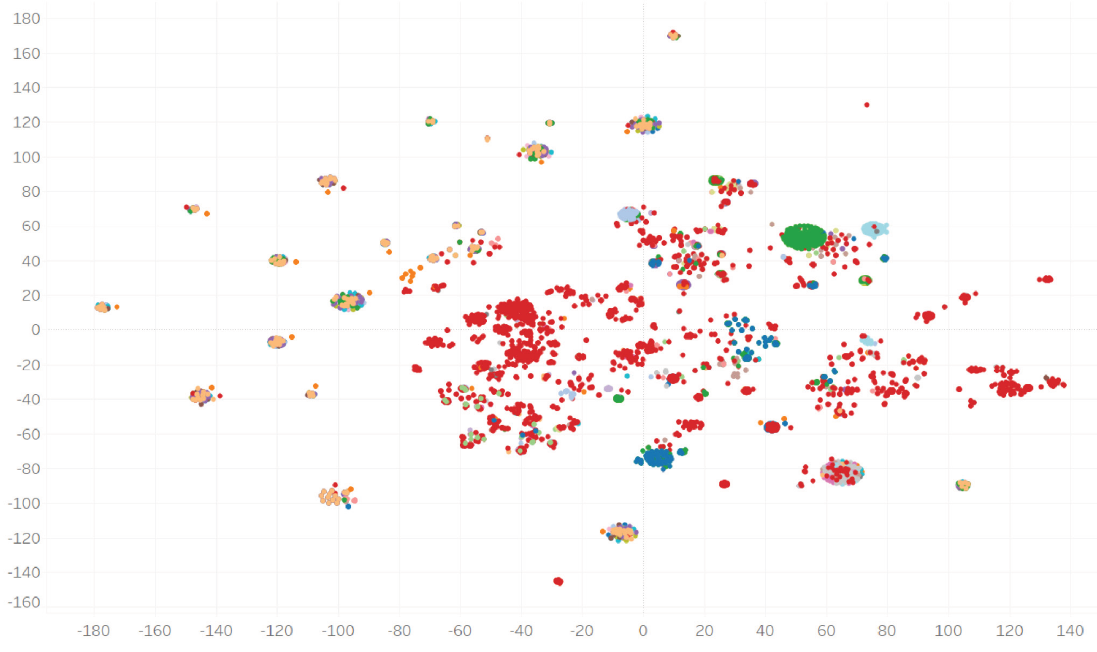
Mamy wyodrębnione grupy (lokalizacja na wykresie – wg cech infrastrukturalnych, kolory – klastry, które uzyskaliśmy wcześniej podczas obróbki tekstu). Widać też zbieżność kolorów i lokalizacji. Przyglądając się bliżej grupce na przecięciu -100 i 20, w tym samym miejscu na wykresie są domeny z tej samej kampanii, lecz o różnych nazwach:
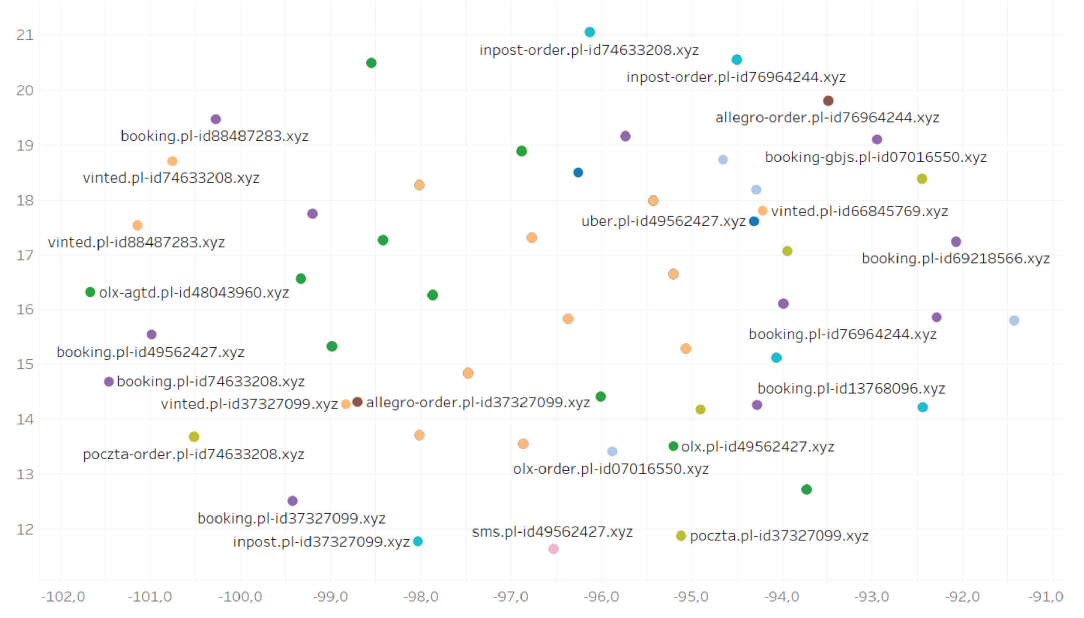
Liczba grupek wydaje się wciąż zbyt duża i za bardzo rozstrzelona, podobne domeny znajdują się też w różnych grupach. Jesteśmy już blisko celu. Zbierzmy zatem wszystkie cechy, zarówno te pochodzące od tekstu, jak i wynikające z innych źródeł, i spróbujmy użyć ich do automatycznego grupowania domen.
Otrzymujemy całkiem zgrabny wykres (kolory wskazują ASN):
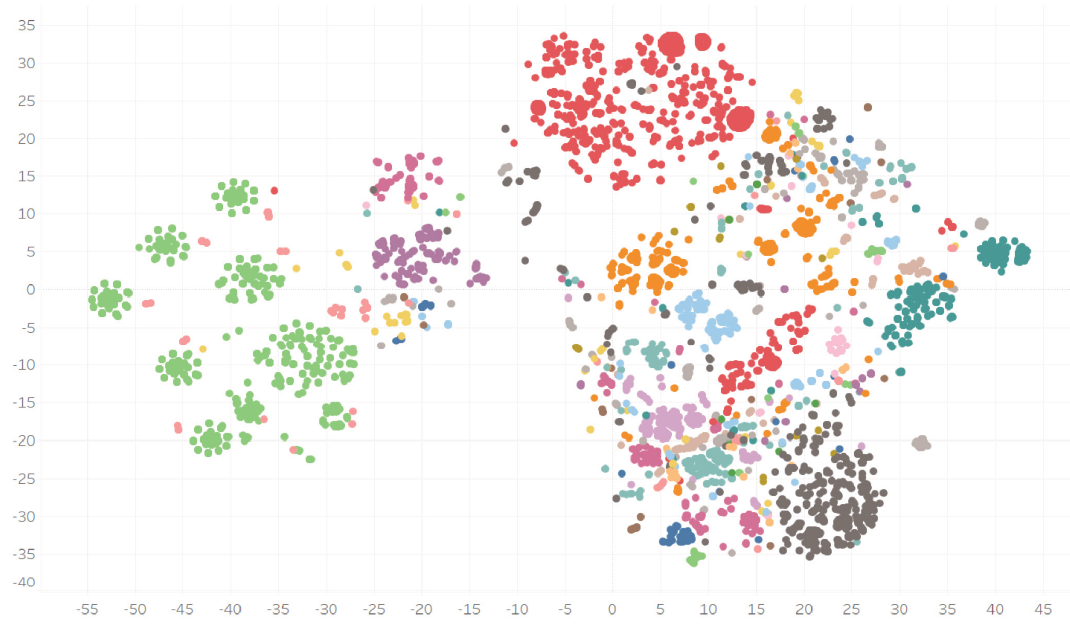
Ten sam wykres z podziałem na nasze wewnętrznie ustalone kategorie:
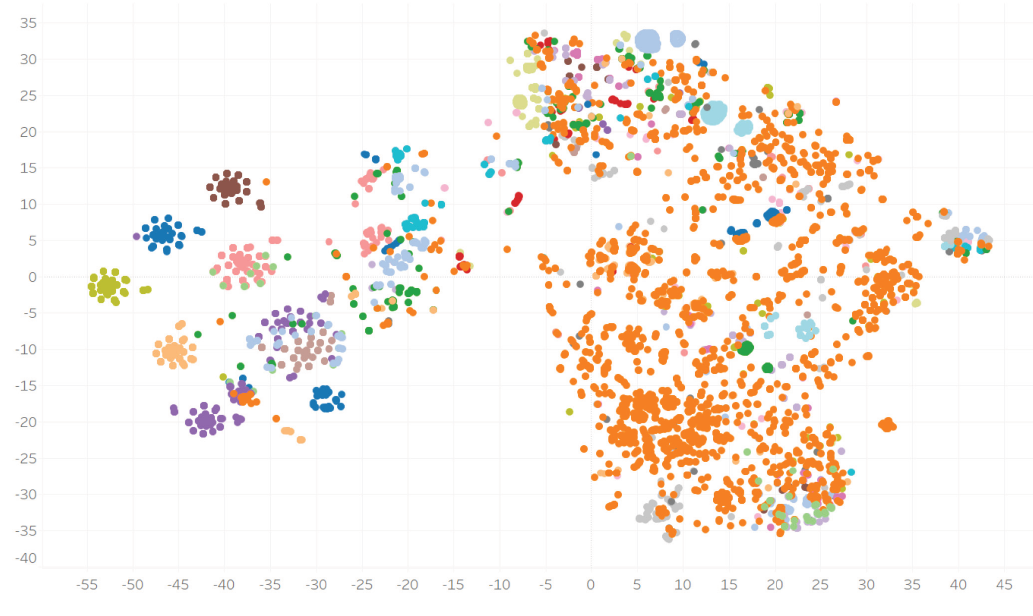
Zbliżenie lewej części wykresu:
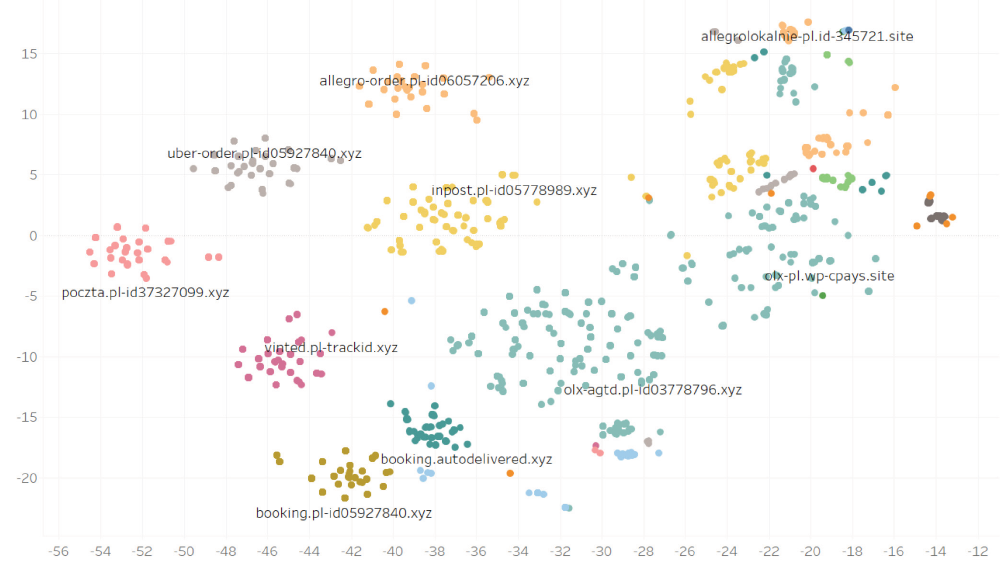
Mimo użycia niezbyt zaawansowanego i niedeterministycznego algorytmu redukcji wymiarów (t-SNE) mamy w jednym miejscu wykresu mikro-grupy domen, które prawie nie różnią się tekstem, natomiast przynależność do tej samej kampanii została jednoznacznie zaznaczona przez cechy infrastrukturalne, które te grupki ustawiły obok siebie. Kolory to nasze wewnętrzne oznaczenie, nietrudno zgadnąć, co poszczególne z nich oznaczają. Potwierdzeniem niech będzie jeszcze wynik zapytania o certyfikaty jednej konkretnej domeny z wykresu.
Dla domeny „pl-id06057206.xyz” wynik z crt.sh wygląda tak:
pl.pl-id06057206.xyz
inpost-order.pl.pl-id06057206.xyz
vinted-order.pl-id06057206.xyz
booking-order.pl-id06057206.xyz
poczta-order.pl-id06057206.xyz
vinted.pl-id06057206.xyz
booking.pl-id06057206.xyz
sms.pl-id06057206.xyz
pl-id06057206.xyz
uber-order.pl-id06057206.xyz
allegro-order.pl-id06057206.xyz
inpost-order.pl-id06057206.xyz
olx-order.pl-id06057206.xyz
Niemal wszystkie prefiksy z listy znalazły się na ostatnim wykresie, bingo! Dosyć prosty algorytm zgrupował te domeny prawidłowo. A skoro jemu się udało, to te bardziej zaawansowane algorytmy poradzą sobie również z klasyfikacją w prawdziwym boju.
Podsumowanie
Mamy zbiór danych, w którym:
a) jest pełna dowolność tworzenia nowych przypadków (tworzą je w większości ludzie, nie maszyny),
b) jest bardzo mała liczba cech łatwo/masowo dostępnych,
c) mamy pewność, że zbiór treningowy zawiera przykłady false negative,
d) wielkość zbioru uczącego jest niemal nieograniczona historycznie i zawsze będzie rosnąć,
e) pojawiają się ciągle nowe schematy, nowe grupy przestępcze etc.
f) nazwa domeny to czasem zaledwie kilka znaków,
g) miliony domen musimy przepuścić przez algorytmy w czasie rzeczywistym
A mimo to algorytmy potrafią wybrać sobie cechy istotne i na ich podstawie podejmować decyzje bardzo trafnie. Do tego stopnia, że w produkcyjnym trybie udział false positive pośród domen-kandydatów nie przekracza 10%. Co więcej, przeszło 50% przypadków jesteśmy w stanie zweryfikować, oznaczyć i zablokować automatycznie – tak bardzo pasują do znanych wzorców. Być może przestępcy są do tego stopnia przewidywalni, a może… (przewrotnie) algorytmy nauczyły się już wzorców zachowań operatorów CyberTarczy i podsuwają dokładnie to czego właśnie oczekują?


