


Sztuczna inteligencja i cyberbezpieczeństwo, czyli każdy kij ma dwa końce

Rok powoli zmierza ku końcowi, pora więc powoli kończyć temat z tegorocznego Raportu CERT Orange Polska. Tym razem przyjrzyjmy się temu jak sztuczna inteligencja może wspomagać walkę z cyberprzestępcami. Oczywiście jak zawsze zapraszamy do lektury całego raportu, który znajdziecie tutaj.
#jasnastronamocy
Wprowadzenie
Zagadnienia związane ze sztuczną inteligencją (ang. Artificial Intelligence – AI), a w szczególności z uczeniem maszynowym (ang. Machine Learning – ML), obecne są w dziedzinie cyberbezpieczeństwa już od 30 lat. Najprostsza forma sztucznej inteligencji w postaci regułowych systemów eksperckich (tak, to też AI!) była podstawą funkcjonowania systemów wykrywania włamań (IDS – Intrusion Detection Systems) już w późnych latach osiemdziesiątych, a dzisiaj gości w systemach klasy SIEM. Uczenie maszynowe (czyli systemy, wykonujące pracę coraz lepiej wraz z nabywanym doświadczeniem) wykorzystywane jest w programach antywirusowych od lat dziewięćdziesiątych, w oparciu o Naiwny Klasyfikator Bayesowski (przewidywanie kategorii w nieznanym zestawie danych). Wiele współczesnych rozwiązań korzysta z wariantów tej techniki, która w najprostszej postaci sprowadza się do elementarnej idei: każde słowo odnalezione w dokumencie ma przypisaną wagę, kojarzącą je z niechcianymi mailami. Niektóre słowa (jak “płatność”, “login”, “faktura”) dużo mocniej niż inne wpływają na zapalenie czerwonej lampki.
Stosowane dzisiaj metody mogą być oczywiście dużo bardziej zaawansowane. Przykładem są aplikacyjne zapory sieciowe (WAF – Web Application Firewall), które wykrywają anomalie jako aberracje od “wyuczonych” przez system profili typowego ruchu, generowanego przez stronę internetową i jej użytkowników.
Magia? Ależ skąd!
Terminy takie jak sztuczna inteligencja, uczenie maszynowe, czy sieci neuronowe brzmią jak magiczne zaklęcia do rozwiązywania wszystkich problemów. Tymczasem jest to zwyczajna mniej lub bardziej skomplikowana matematyka. Na przykładzie problemu klasyfikacji maili phishingowych opiszemy, jak wygląda to w praktyce.
Przeciwdziałanie kampaniom phishingowym polega przede wszystkim na blokowaniu tworzonych przez przestępców stron WWW, wyłudzających dane. Aby móc tego dokonać, konieczna jest jednak ich uprzednia identyfikacja. Realizowane jest to m.in. przez jednostki SOC i CERT, które zajmują się analizą potencjalnych zagrożeń. Cennym źródłem wiedzy są też serwisy takie jak OpenPhish, PhishTank, czy chociażby Twitter, gdzie badacze z całego świata wymieniają się informacjami o domenach stosowanych przez przestępców.
Co jednak w przypadku, gdy pojawia się zupełnie nowa kampania, której nikt wcześniej nie obserwował? Gdy przestępcy tworzą kolejną stronę, która nie była przez nikogo raportowana, a próbki kampanii nie dotarły jeszcze do SOC czy CERT? Czy jedyne co możemy zrobić, to czekać na pierwszych poszkodowanych użytkowników, aby analizując ich przypadek rozpoznać i zablokować stosowane przez przestępców zasoby?
W przypadku nowych zagrożeń, z pomocą przychodzi nam AI. Na podstawie zdarzeń historycznych algorytmy uczą się, na jakie cechy warto zwracać uwagę, a które są nieistotne z punktu widzenia klasyfikacji maili. I nie chodzi tu tylko o występowanie konkretnych słów kluczowych (takie algorytmy łatwo oszukać), ale także o takie cechy maila, jak struktura, kodowanie, budowa zawartych w nim adresów URL i wiele innych.
Zadanie rozpoczynamy od zebrania i opisania zbioru maili, którymi zasilimy nasz algorytm. Jako przykładu użyjemy zebranej w celach szkoleniowych próbki maili zgłoszonych przez pracowników i zweryfikowanych jako podejrzane. Klasę przeciwną będzie stanowiła próbka pozostałych maili o podobnej liczności. Przygotowując taki zbiór, musimy pamiętać o jego wyczyszczeniu – usunięciu powtarzających się maili, eliminacji błędnych danych itp. Każdą z wiadomości opisujemy przy pomocy liczb odpowiadających jej poszczególnym cechom:
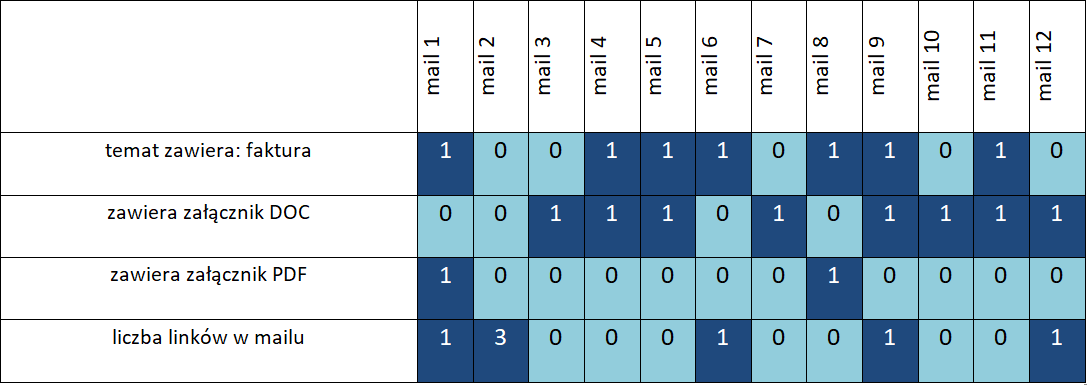
Oczywiście w praktyce ilość zebranych danych historycznych sięga setek tysięcy wiadomości, a liczba cech opisujących każdy z nich liczona jest w dziesiątkach albo setkach. Rysunek 2 prezentuje nasz zbiór liczący ok. 800 maili, z których połowa to maile phishingowe. Każda z kolumn wykresu to jeden mail, a każdy z 80 wierszy to jedna z cech, takich jak występowanie konkretnego słowa kluczowego, wielkość maila, liczba zawartych w nim odnośników itd. Wyraźnie widać, że układ cech maili phishingowych (zgromadzonych na prawej połowie wykresu) istotnie różni się od cech pozostałych maili.

W kolejnym kroku algorytmu dokonujemy automatycznego wyboru tych cech, które jak najskuteczniej rozdzielają oba zbiory. W przypadku naszego zestawu algorytm uznał, że do takiego rozdzielenia wystarczą tylko 23 cechy (zobrazowane na kolejnym rysunku). Z oczywistych względów nie możemy ujawnić jakie to parametry 🙂

W następnym etapie należy wybrać model, adekwatny do rozwiązywanego problemu i na podstawie określonych cech dokonać estymacji jego parametrów. Parametry są ustalane w taki sposób, aby dla konkretnych danych uczących (zbioru, dla którego elementów mamy wiedzę, które z nich należą do której klasy) zminimalizować liczbę elementów błędnie sklasyfikowanych.
Model posłuży nam do przyporządkowania nowych maili do klasy phishing/nie-phishing. Dysponując dodatkowym zbiorem wiadomości testowych, możemy zweryfikować poprawność naszego modelu, obliczając tzw. macierz błędów, informującą o tym, jak dokładny jest nasz model. W tym celu przetestowaliśmy model na dodatkowych 250 mailach (w proporcji 50 /50). Wyniki działania przedstawiają się następująco:

W niemal 95% przypadków nasz algorytm poprawnie zaklasyfikował maile testowe. Niestety, zdarzały się również przypadki, gdzie maile phishingowe zostały przez algorytm przepuszczone jako „czyste”, a także maile prawidłowe, które uznał za phishing.
Żaden algorytm nie jest w stu procentach skuteczny. Stosowanie AI nie zwalnia nas z konieczności zachowania ostrożności. Sztuczna inteligencja daje nam poważne wsparcie w przetwarzaniu olbrzymiej ilości zdarzeń, ale nadal pozostaje pewien margines niepewności otrzymywanych odpowiedzi. Dlatego w przypadku podejmowania decyzji krytycznych, nadal jest potrzebna interwencja człowieka.
#ciemnastronamocy
Nieraz spotykamy się z sytuacją, kiedy nowe rozwiązanie lub technologia, która w zamierzeniu ma ułatwiać nam życie, szybko stanowi pożywkę dla przestępców. Ciekawym przykładem od strony technicznej ataków są np. nazwy domen internetowych zawierające znaki poza ASCII (IDN – Internationalized Domain Name). i ich upowszechnienie w przeglądarkach WWW, doprowadziło do ataków phishingowych, gdzie często nie można odróżnić adresu wyświetlanej przez nas strony od oryginału. Sprawdź, co widzisz na pasku z adresem strony, po wpisaniu wyglądającego mocno podejrzanie https://www.xn--80ak6aa92e.com/?
Innym przykładem, tym razem dotyczącym motywacji ataków, jest bankowość elektroniczna i jej bardziej egzotyczna odmiana – kryptowaluty. Stają się one łatwym celem grabieży, a ponadto pozwalają cyberprzestępcom wykorzystać zainfekowane komputery dosłownie jako kopalnie pieniędzy. Tego typu przykłady można mnożyć.
Co z uczeniem maszynowym i sztuczną inteligencją (AI)?
Po upowszechnieniu się na przełomie XX i XXI wieku filtrów antyspamowych opartych o metody Bayesowskie (“Bayesian Spam Filtering” – więcej piszemy o tym wyżej, przy #jasnastronamocy) natychmiast narodziły się pomysły, jak takie systemy przechytrzyć.
Jedna z metod to “Bayesian poisoning” która polega na uzupełnieniu wysyłanego maila o słowa kluczowe silnie wygaszające wspomnianą “czerwoną lampkę”. Inne to np. przeniesienie części “niechcianego” słowa kluczowego (wyraźnie sugerującego spam) do nowego wiersza, wprowadzenie w nim drobnej literówki czy zapisanie go w postaci obrazka. Współczesne systemy detekcji spamu i phishingu biorą oczywiście poprawki na tego typu metody, np. posiadają komponenty OCR do wykrycia tekstu zapisanego na obrazkach.
Mechanizm działania filtrów opartych o Naiwny Klasyfikator Bayesowski jest bardzo prosty, więc i przechytrzyć go jest raczej łatwo. Niestety, bardziej wyrafinowane modele, np. oparte o głębokie sieci neuronowe (Deep Neural Networks) też mogą być podatne na przykłady skonstruowane w wyjątkowo “złośliwy” sposób. “Adversarial Machine Learning” wyrasta właśnie na całą dziedzinę badań. Przykładem, który doskonale ilustruje potencjalne zagrożenie, jest atak na system rozpoznawania znaków drogowych. Znak drogowy “stop” poprawnie rozpoznawany przez system jest przetworzony w sprytny sposób na obraz niemal nieodróżnialny dla ludzkiego oka, ale przez sieć neuronową rozpoznawany jako “ustąp pierwszeństwa” (jego amerykańska wersja różni się kolorystycznie od tej znanej w Europie).

Źródło: Nicolas Papernot, Patrick D. McDaniel, Ian J. Goodfellow, Somesh Jha, Z. Berkay Celik, Ananthram Swami: Practical Black-Box Attacks against Deep Learning Systems using Adversarial Examples. CoRR abs/1602.02697 (2016).

Odporność na tego typu ataki jest kluczowa w systemach ochrony zdrowia, militarnych, biometrycznych, finansowych, cyberbezpieczeństwie, internetu rzeczy, pojazdów autonomicznych, inteligentnych budynków i miast. Nic jednak nie pozostaje bez odpowiedzi – badania nad konstrukcją “złośliwych przykładów” w machine learningu owocują też zrozumieniem tego jak budować modele i systemy bardziej odporne na takie techniki.
Cyberprzestępcy starają się przechytrzyć systemy bezpieczeństwa oparte o machine learning – ale i on jest coraz częściej narzędziem w ich rękach. Przykładem tego są systemy OCR łamiące zabezpieczenie CAPTCHA, które w założeniu ma być testem Turinga, ograniczającym wpływ botów na strony internetowe.
Aby odnieść adversarial machine learning do świata bezpieczeństwa teleinformatycznego trzeba wspomnieć o wykorzystywaniu ML do tworzenia kodu, który ma je omijać, wykrywający złośliwy kod lub narzędzia, które go sprawdzają (sandboxy).
Wojna cybernetyczna, której celem jest destabilizacja kluczowej infrastruktury i gospodarki, wykorzystuje złośliwe oprogramowanie oraz blokowanie usług (DDoS). Powiązana jest z nią ściśle wojna informacyjna, której szczególnym przypadkiem jest szerzenie propagandy. Obecnie takie ataki są przeprowadzane m.in. przez ludzi trollujących komentarze na opiniotwórczych portalach. Deep fake wyniesie ten rodzaj zagrożeń na nowy poziom. Dzięki wykorzystaniu deep learningu będzie możliwe włożenie dowolnych słów w usta dowolnego polityka, a fikcja będzie niemożliwa do odróżnienia od rzeczywistości. Przykłady wykorzystania deep fake pokazują z jaką łatwością można to robić nawet w czasie rzeczywistym.

Więcej przykładów do czego przestępcy mogliby wykorzystywać ML można znaleźć np.: https://www.welivesecurity.com/wp-content/uploads/2018/08/Can_AI_Power_Future_Malware.pdf – wybieranie celów ataków, uczenie się jak zachowuje się sieć, żeby wpasować się ze swoim ruchem i nie dać wykryć NBADom itd.
Nie możemy liczyć, że sztuczna inteligencja to panaceum, które rozwiąże za nas problemy. Dzisiaj to tylko narzędzie. To poniekąd cieszy – bo nie powinniśmy się obawiać, że użyta w złym celu będzie niepokonana. Czeka nas jednak nieustanny wyścig, w którym nigdy nie możemy pozostawać w tyle.
Mam jednak obawy związane z AI, a dotyczą one innych kwestii. Zapominając na chwilę o kontekście cyberbezpieczeństwa, zauważmy jak szybko komputer zastępuje człowieka w kolejnych dziedzinach życia – programy potrafią już dzisiaj same tworzyć np. piękną muzykę.
Wiążąc temat sztucznej inteligencji z szerzej rozumianym ryzykiem, wspomnę też o ryzyku egzystencjalnym.
Elon Musk, współzałożyciel firmy badawczej OpenAI, której celem jest opracowanie “przyjaznej” sztucznej inteligencji, jest jednym z nielicznych dzisiaj głosów opowiadających się otwarcie za wprowadzeniem regulacji dotyczących AI.
Jeśli SI w jakiejkolwiek formie będziemy chcieli powierzyć “wolną wolę”, musimy tworzyć ją w sposób odpowiedzialny.
| Istnieją bardzo nośne hasła (buzzword), które są niejednoznaczne, bardzo obszerne i ewoluują w czasie, ale które wszyscy znają i kojarzą. Przykładem są pojęcia sztucznej inteligencji (Artificial Intelligence) i Big Data. Odnoszą się one do dziedziny wiedzy zwanej nauką o danych (Data Science). Proces pozyskiwania tej wiedzy to na przykład eksploracja/wydobywanie danych (Data Mining) wykorzystująca algorytmy maszynowego uczenia się (Machine Learning). Szczególnym przypadkiem jest głębokie uczenie się (Deep Learning) wykorzystujące między innymi algorytmy głębokich sieci neuronowych (Deep Neural Networks). Data Science to także statystyka, wizualizacja danych czy analityka biznesowa. |


